A Internet está em um ponto de inflexão. O aumento contínuo do bloqueio de anúncios pôs fim ao modelo de receita, que depende apenas do dinheiro do anúncio para operar sites e empresas.
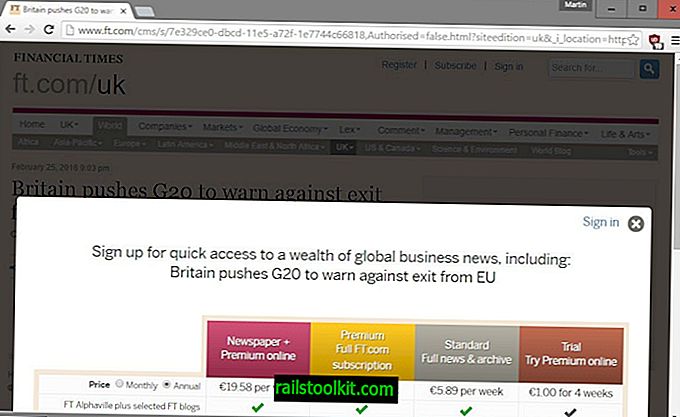
Especialmente sites de notícias começaram a experimentar maneiras de diversificar fontes de renda, e uma opção importante que sites como o Wall Street Journal, o Financial Times, o New York Times ou o Washington Post implementaram é o sistema de paywall.
Existem diferentes tipos de paywalls, mas todos têm em comum que bloqueiam o acesso ao conteúdo diretamente ou após a leitura de um certo número de artigos no site.
Os visitantes são solicitados a se inscrever no site para continuar lendo os artigos.
Pode fazer sentido do ponto de vista comercial e ser mais lucrativo do que lutar contra usuários que executam bloqueadores de anúncios, mas há uma desvantagem tanto para o site pago quanto para o usuário bloqueado.
Os sites perdem uma alta porcentagem de visitantes se implementarem um sistema de paywall. Não está claro qual é a porcentagem realmente alta e provavelmente varia de site para site, mas é provavelmente muito superior à porcentagem de visitantes que se inscrevem no site depois de terem a opção de se inscrever para ler o artigo desejado.
Mascarar seu navegador
Não é segredo que sites de notícias permitem o acesso a agregadores de notícias e mecanismos de pesquisa. Se você verificar o Google Notícias ou a Pesquisa, por exemplo, encontrará artigos de sites com paywalls listados lá.
No passado, os sites de notícias permitiam acesso a visitantes provenientes de grandes agregadores de notícias como Reddit, Digg ou Slashdot, mas essa prática parece ser tão boa quanto morta hoje em dia.
Outro truque, colar o título do artigo em um mecanismo de pesquisa para ler diretamente a história em cache, não parece mais funcionar corretamente, assim como os artigos em sites com paywalls geralmente não são mais armazenados em cache.
Atualização : O Wall Street Journal anunciou que irá tapar o buraco descrito abaixo. No entanto, você ainda pode ler artigos por trás do paywall do site, usando o seguinte método:
- Pressione F12 quando estiver na página do artigo com o artigo cortado e com a solicitação de inscrição para lê-lo na íntegra.
- Abra a guia do console.
- Cole o javascript: window.location = "// m.facebook.com/l.php?u="+encodeURIComponent(window.location.href);
- Pressione Enter.
A página deve ser recarregada e o artigo deve ser carregado por inteiro. Você também pode postar o link do artigo no Facebook, por exemplo, em um novo post que somente você pode ver. Ao clicar no link publicado, o artigo deverá ser carregado inteiramente no site do Wall Street Journal.
Agente do usuário e referenciador
Você provavelmente está se perguntando como os sites bloqueiam ou permitem o acesso ao conteúdo do site. Os métodos foram aprimorados ao longo dos anos e não basta mais alterar o referenciador do navegador para //www.google.com/ para obter acesso total ao conteúdo de um site.
Em vez disso, os sites usam várias verificações que incluem agente do usuário, referenciador e cookies, e às vezes até mais do que isso, para determinar a legitimidade do acesso.
Informação geral
Provavelmente, a melhor maneira de mascarar o navegador é fazê-lo parecer o Googlebot.
- Referenciador: //www.google.com/
- Agente do usuário: Mozilla / 5.0 (compatível; Googlebot / 2.1; + // www.google.com/bot.html
Raposa de fogo
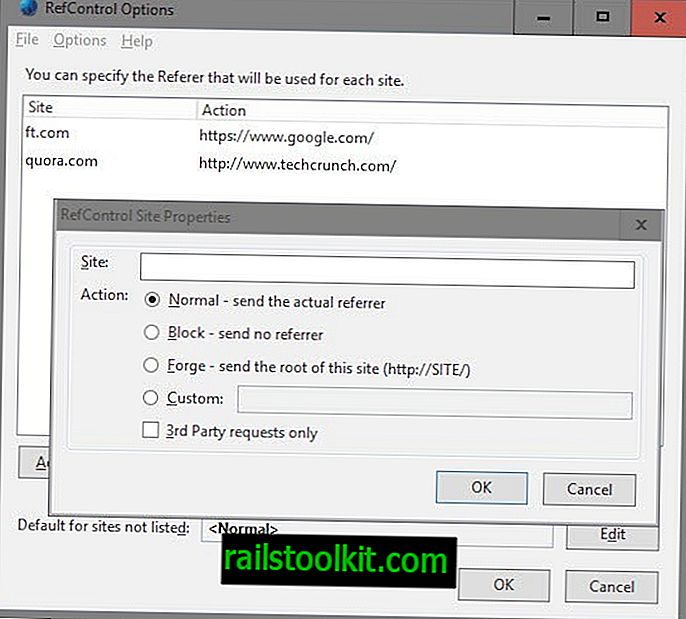
Os usuários do Firefox precisam de dois complementos de navegador para isso: o primeiro, RefControl, para alterar o valor do referenciador ao visitar sites de notícias, o segundo, User Agent Switcher, para alterar o agente do usuário do navegador.
- Baixe e instale as duas extensões no navegador Firefox.
- Toque na tecla Alt e selecione Ferramentas> Opções de controle de ref.
- Clique em "adicionar site", digite um nome de domínio em site, selecione ação personalizada e digite //www.google.com/ como o referenciador.
- Repita isso para todos os sites de notícias que você deseja acessar (alguns podem não funcionar, mesmo que você faça as alterações, lembre-se disso).
- Quando terminar, feche a janela de configuração.
- Toque na tecla Alt novamente e selecione Ferramentas> User Agent padrão> Editar agentes do usuário no menu.
- Selecione Novo> User Agent e substitua a sequência no campo User Agent por Mozilla / 5.0 (compatível; Googlebot / 2.1; + // www.google.com/bot.html). Nomeie-o Googlebot.
- Saia do menu.
- Antes de acessar esses sites, toque em Alt e selecione Default User Agent> Googlebot.
Isso é tudo o que existe. É um pouco lamentável que não exista uma extensão para o Firefox que mude o agente do usuário automaticamente com base nos sites que você visita.
Google Chrome
Os usuários do Google Chrome podem instalar extensões, como User Agent Switcher e Referer Control, disponíveis para o navegador fazer o mesmo.
Há, no entanto, outra possibilidade, que é criar uma extensão personalizada que automatize o processo no navegador.
As instruções são fornecidas em Elaineou. Basicamente, basta criar um novo diretório no computador local, criar os dois arquivos background.js e manifest.json dentro dele, copiar e colar o código encontrado no site nos arquivos.
Você precisa ativar o "modo de desenvolvedor" no chrome: // extensions / e, em seguida, pode selecionar "load unpacked extension" para escolher a pasta em que você criou os dois arquivos para carregar a extensão no Chrome.
Você pode modificar a lista de sites suportados para adicionar novos.